
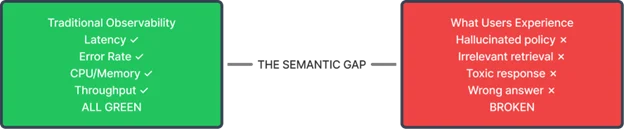
Your dashboards are green. Latency is nominal. Error rates are flat. Yet your users are furious because your AI chatbot just confidently invented a refund policy that doesn’t exist.
Welcome to the semantic gap — the blind spot that traditional observability cannot see.
The Problem With Green Dashboards
Traditional APM is built on a deterministic contract between the system and operator. If a microservice throws a 500 error, something broke. If latency spikes by 400%, users are suffering. Tools such as Prometheus and Datadog capture these system behaviors seamlessly.
LLMs break that contract.
An AI service can process a request with perfect latency, consume standard memory, and return an HTTP 200 OK — while failing the user completely. It might hallucinate a policy, retrieve irrelevant context, or deliver toxic advice. The system is healthy; the application is broken.
Platform teams relying solely on rate, errors, and duration (RED) metrics remain blind to these failures until a support ticket is filed — or a lawsuit is served.
From System Health to Semantic Quality
Scaling AI responsibly requires extending observability from Is it running? to Is it working? For platform engineers, this means instrumenting three new signal types that traditional stacks miss.

1. Semantic Quality Scores
For RAG-based services, you must track retrieval relevance — did the context actually answer the question? For generative services, measure faithfulness — is the response grounded in retrieved documents, or is the model improvising? These scores must flow into Prometheus alongside latency percentiles. A drop in faithfulness demands the same alerting urgency as a spike in error rates.
2. Drift Detection
Model behavior degrades over time — not because you deployed bad code, but because the world changed. User queries shift. Source documents get stale. Embedding distributions drift. Yesterday’s well-tuned RAG pipeline is today’s hallucination factory. Your platform must capture baseline distributions at deployment and alert immediately when production diverges.
3. Token Economics
A runaway prompt burns through budget faster than a memory leak burns through RAM. Yet, most stacks treat AI costs as a finance problem discovered weeks later. Real-time token telemetry catches anomalies — recursive agent loops, prompt injection attacks and context inflation — while they are still containable.
The Wake-Up Call: Garcia v. Character.AI
Why is this urgent? It is because the legal landscape has shifted fundamentally.
In May 2025, a federal ruling in Garcia v. Character Technologies sent shockwaves through the industry. Judge Anne Conway ruled that AI chatbots are products — not protected speech — and are subject to the same liability standards as a toaster or a car.
The court rejected the argument that chatbot outputs are First Amendment-protected expressive speech, allowing wrongful death and product liability claims to proceed. The precedent is stark: Your AI’s outputs can make your company liable under product defect laws.

For platform teams, this transforms responsible AI from an ethical nice-to-have into a hard product safety requirement. You cannot simply add a disclaimer and hope for the best. The platform must provide technical guardrails to prevent harmful outputs — and the observability to prove your systems attempted to catch them.
Why This is a Platform Problem
Here is the trap: Treating semantic observability is something application teams should figure out for themselves.
- If developers must remember to add quality scoring, they won’t.
- If drift detection requires a custom implementation per service, it will be inconsistent.
- If token monitoring is optional, nobody opts in until the budget explodes.
The same logic that makes security and reliability platform concerns applies here. Your Golden Paths must include AI observability by default. When a developer deploys an inference service through your IDP, they should automatically inherit semantic metrics, drift baselines and cost telemetry — just as they inherit logs and traces today.
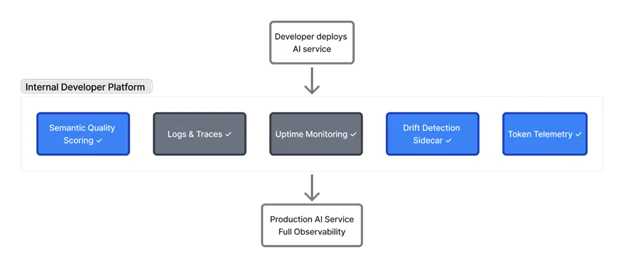
Making it Default
The implementation pattern is straightforward:
- Wrap inference endpoints with lightweight evaluation that scores responses before returning them.
- Deploy drift detection as a sidecar that processes asynchronously, avoiding latency penalties.
- Emit token consumption as first-class metrics segmented by model, endpoint and team.
The OpenTelemetry GenAI semantic conventions provide a vendor-neutral schema for this. Instrument once, stream to any backend. Your existing Grafana dashboards can visualize faithfulness scores right next to p99 latency.
The hard part isn’t the technology — it’s the mandate. Platform engineering promises to encode best practices into the path of least resistance. For AI services, semantic observability is no longer a feature request; it is table stakes.
Your services may be up, but the question is whether they are working. Your observability stack must answer both.