
Platform engineering is gaining traction across industries. Enterprises are investing in internal developer platforms (IDPs) to improve developer experience, reduce cognitive load and scale safe software delivery.
But many early-stage platform teams are building on shaky foundations. One of the most common pitfalls we see is what we call the platform façade: Stitching together a developer portal, some workflow automation and a handful of continuous integration/continuous delivery (CI/CD) pipelines and calling it a platform.
It looks good in demos. It checks some self-service boxes. It even unblocks teams in the short term. But under the hood, it lacks the orchestration, lifecycle guarantees and operational resilience required for a platform to succeed long-term.
Automation is Not the Same as Orchestration
Whether it’s a workflow engine like Argo Workflows or SonataFlow, a CI/CD pipeline like Jenkins or GitHub Actions, each of these tools is designed to execute sequences of steps. They can deploy applications, spin up infrastructure, and even trigger complex integrations.
But they don’t manage state across the platform. They don’t enforce policy. They don’t track ownership or orchestrate the full lifecycle of a capability. In a healthy platform, pipelines are ephemeral; the platform itself is persistent. Without orchestration, automation becomes brittle, fragmented and difficult to evolve.
Portals Without Platforms Are Just GUIs and Glue
Developer portals such as Spotify’s Backstage or Atlassian’s Compass improve discoverability and create a better user experience for developers. But without a platform layer that enforces standards, manages state and oversees day-to-day operations, these portals risk becoming front doors to fragile glue code.
Clicking a button in a portal may provision a service, but:
- Is it compliant with current policy?
- Can it be upgraded without disruption?
- Who owns it after it’s created?
Without clear answers, self-service becomes self-sabotage.
The ‘Puppy for Christmas’ Problem
We call this self-sabotage the ‘puppy for Christmas’ problem: It’s easy to provision a service with a click in a portal, but someone must feed it, clean it and care for it over time.
In many portal-and-pipeline setups, ‘you clicked it, now you own it’ becomes the unwritten rule. Developers inherit operational responsibility for components they didn’t design and may not have the expertise to maintain.
The result:
- Orphaned resources that cost money or pose security risks
- Misconfigurations and drift from compliance baselines
- Developers spending more time on maintenance than on delivering business value
From Automation to Orchestration
To avoid the platform façade, teams must move from automation to orchestration. Here’s how the two approaches compare, framed around the four key platform pillars of speed, safety, efficiency and scalability:
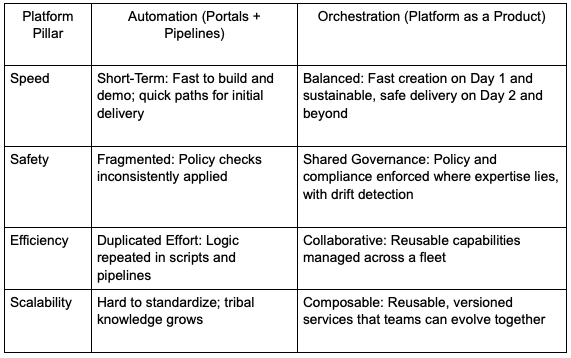
Building a Platform That Lasts
A lasting platform isn’t just a collection of tools stitched together; it’s a product, with a clear purpose, defined boundaries and measurable outcomes.
The most effective platforms share several key characteristics:
- Focus on both Day 1 and Day 2 speed:
Speed isn’t just about creating something quickly (Day 1). It’s also about evolving and maintaining it without friction (Day 2). A platform should make both equally smooth.
- Clear contracts and APIs:
Every interaction between application teams and the platform should be defined and predictable. This reduces ambiguity, enables teams to work in parallel and facilitates easier evolution of the platform without disrupting existing workloads.
- State awareness and reconciliation:
The platform should know what’s been deployed, whether it’s still compliant with policies and if it has drifted from its desired state. When drift occurs, the platform should be able to reconcile automatically or flag the change for review.
- Policy enforcement where the expertise lies:
Governance should be baked into the platform experience, not bolted on. Policies need to be enforced at the right point in the workflow, by the teams with domain expertise, rather than being dictated from a central authority with no context.
- Lifecycle guarantees:
Provisioning is only the start. Platforms should manage upgrades, patching, deprecation and eventual retirement of resources. Day 2 and beyond are where operational maturity is proven.
- Shared ownership between platform and application teams:
A platform works best when it’s built with platform democracy in mind. Platform teams provide safe, reusable building blocks, and application teams can extend or compose them to meet their needs without bypassing governance (often via embracing inner sourcing principles).
By embedding these principles, you can create more than just a delivery mechanism. You can build a foundation that developers trust, which will evolve with business needs and can avoid the slow erosion into the platform façade.
When a platform lasts, it’s not because it resists change; it’s because it’s designed to change safely, at scale, over time.