
Use of AI starts with a curious engineer who wants to improve their productivity. Eventually, more and more developers begin to use AI for improving and reviewing code, generating tests, or automating operational tasks. However, increased usage of AI also increases the security risk. What processes, systems, and patterns can help mitigate the risks while supporting our usage of AI?
AI involves three pillars: Tools, context, and patterns. Tools include the Model Context Protocol (MCP), while context includes skills, prompts, and memory. Patterns involve AI orchestration, retrieval augmented generation (RAG), role-based access control (RBAC), and more. Standardizing each of these pillars across a development workflow and runtime becomes a critical requirement to scaling and securing AI use within an organization. For example, not standardizing on observability for a coding agent may make it difficult to identify potential context poisoning or privilege compromise. The approach to mitigating the risks of AI involves shifting down parts of these pillars as a shared concern across platform and security.
AI for Productivity, AI as a Product
AI not only becomes a tool to improve productivity but also a capability of our platform and security. From a platform engineering perspective, you can use AI to improve your ability to manage and change your platform. This might include writing infrastructure as code with a coding agent, translating Kubernetes deployments to ArgoCD rollouts, or using an AI agent for cluster operations. As a common use case, AI for productivity means that as an end user, you need to have some knowledge of how to engineer the correct prompts, refine agent skills, and pass in important context to get a useful response.
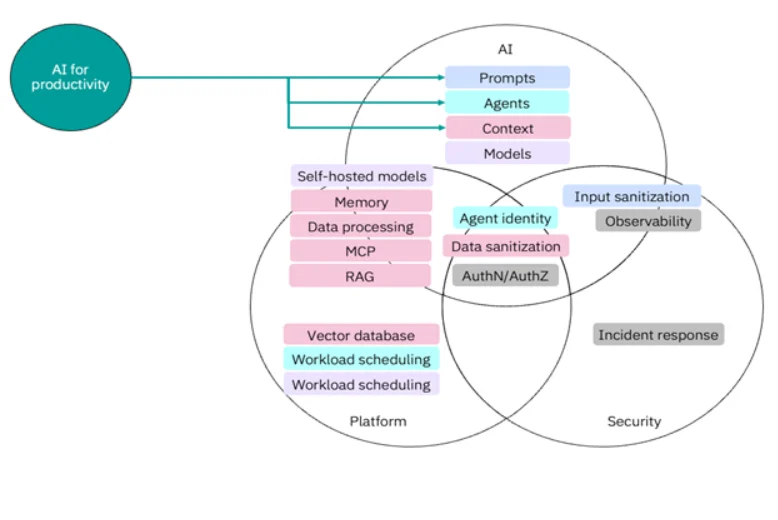
However, as more engineers and developers use AI for productivity, you need to shift down standard AI guardrails and automation as security and platform concerns.
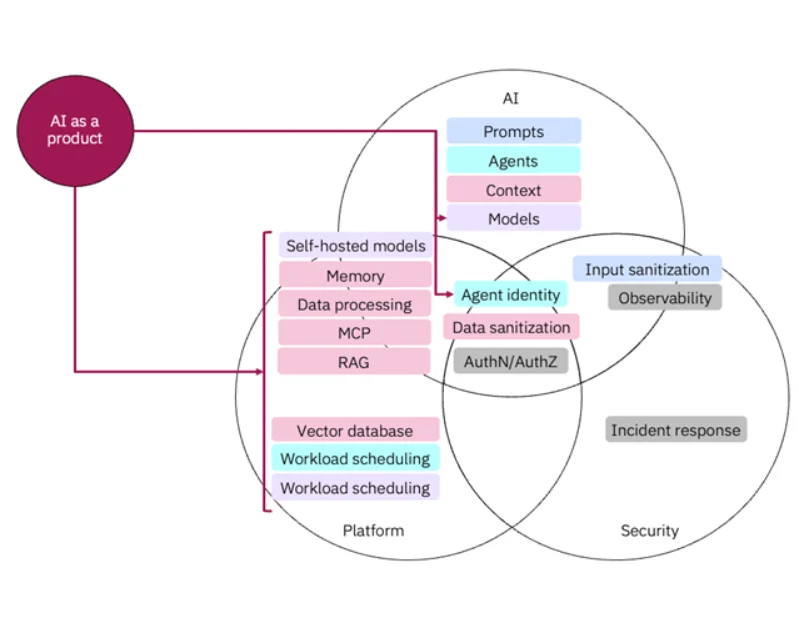
AI becomes a product offering of the platform, complete with standardization, guardrails, and observability. Each team becomes responsible for its own AI use but the security and standardization of it becomes a shared concern.
Sharing Responsibility Between Platform and AI
Shifting parts of your AI implementation into platform engineering ownership earlier in adoption helps set a foundation for scaling AI use across your organization. While AI engineering may have some opinions on the kind of vector database to use for retrieval augmented generation (RAG), platform engineering sets a standard configuration for a vector database with enough flexibility to customize the size, schema, or embedding model. Similarly, a platform team must consider workload scheduling with GPUs for agents or self-hosted models, offering a standard set of options for teams wanting to use AI. Setting early standards for the vector database and workload scheduling helps with cost optimization and offers visibility into common AI use cases.
Platform and AI teams also have joint responsibilities for other components, including data processing, Model Context Protocol (MCP) server discovery, and RAG infrastructure. While data processing may require specialist knowledge, creating a standard pipeline and tooling to process data with common formats ensures that any team member can use it for context. Similarly, creating MCP servers for specific capabilities provides a common data source for agents to retrieve information. Maintaining short-term and long-term memory for AI agents requires platform engineering and AI expertise, as you must understand the scope and storage requirements for conversation flows and users.
As you continue to expand your AI use across the organization, you may choose a hybrid model approach where you mostly use LLM services but some self-hosted LLMs or small language models (SLMs). This requires additional workload scheduling capabilities from a platform perspective and decision-making between AI and platform teams on which models to offer.
Security – Everyone’s Responsibility
Both security and AI teams must bring expert knowledge to understand how to best secure internal AI uses. Both teams must decide how to sanitize inputs from prompts and data for RAG before use, when possible. From a data privacy perspective, understanding what information already exists and needs additional processing for security and access helps maintain regulatory and security requirements.
As you scale AI workloads and use cases, consider an identity framework for agents, servers, and other workloads. For example, assigning SPIFFE identities to agents and setting up authorization through an OpenID Connect or OAuth 2.0 provider ensures that each workload authenticates to the provider and receives a delegated set of permissions to access other systems. A single identity framework also enables observability. Tracing and auditing agent calls to various systems from different prompts requires standardization and implementation from a platform perspective.
Shifting down other requirements of AI to the platform help provide a single interface for authorization and authentication. For example, you may use an AI gateway to discover MCP servers and models. You could also use Agent2Agent protocol for agent discovery. Authentication and authorization becomes a critical part of an AI platform, since agents can communicate with MCP servers, models, and other agents.
Conclusion
You often get the benefit of AI when you apply it to tasks that you have already automated, consolidated, observed, and documented. Our current challenge involves enabling others to use AI while mitigating its risks. By shifting down certain capabilities as a shared platform and security responsibility to support AI, you can define a common set of tools, context, and patterns across your organization. To learn more about how platform engineering helps scale AI, read about how GEICO’s infrastructure team is building platform foundations for their AI-driven future or check out a multitude of other platform engineering success stories.