
Self-service infrastructure was one of platform engineering’s early victories. Give developers golden paths, curated catalogs and well-guarded guardrails, and they stop waiting for tickets, ops teams stop becoming bottlenecks and engineering velocity compounds. The model worked because humans are, at their core, forgiving consumers. They can interpret ambiguous error messages, recognize when a UI is broken, retry a failed workflow and ask a colleague when the docs fall short.
Autonomous agents cannot.
With AI agents moving from novelty to necessity — provisioning environments, running deployments, orchestrating multi-step workflows and operating infrastructure with no human in the loop — platform engineering teams are discovering that the self-service model they spent years building wasn’t designed for this consumer. The result is a growing category of silent failures: Agents that stall on ambiguous responses, hallucinate retry logic, quietly consume resources and fall outside every access policy ever written.
Consider an autonomous deployment agent responsible for provisioning ephemeral preview environments. A transient timeout during environment creation triggers an automatic retry. Since the platform lacks idempotency guarantees, the retry provisions duplicate GPU-backed environments across multiple regions. The agent interprets the partial failure as incomplete execution, continues retrying and silently exhausts regional quotas while generating unexpected cost for hours before a human notices. The failure leaves no obvious trace in any human-facing dashboard. This is not a hypothetical edge case; it is a category of incident that becomes routine when platforms built for human consumers start serving autonomous ones.
This article is a practical design guide for what changes when your platform’s primary consumer is an AI agent. It covers API contract design, identity and access management (IAM) for non-human principals, machine-readable golden paths, observability for agent-driven actions and the governance frameworks needed to keep autonomous infrastructure safe at scale.
This shift is accelerating because modern AI agents are increasingly connected directly to CI/CD pipelines, infrastructure APIs, deployment workflows and internal developer platforms through tool-calling architectures, orchestration frameworks and protocols such as the model context protocol (MCP). The result is that agents are no longer advisory systems sitting beside infrastructure; they are becoming active infrastructure operators, with the ability to provision resources, modify configurations and trigger deployments at machine speed and scale.
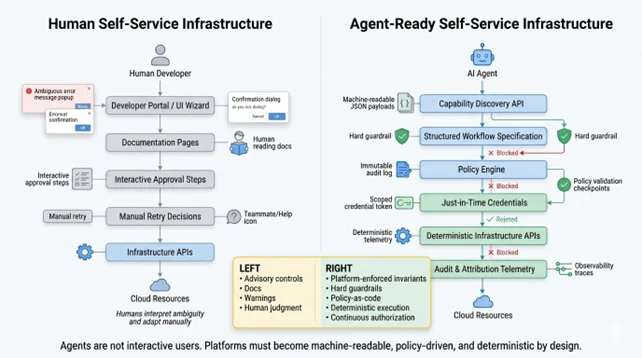
Figure 1: Human Self-Service Infrastructure vs. Agent-Ready Self-Service Infrastructure
The Fundamental Design Gap
Most internal developer platforms were conceived with a specific mental model: A human engineer working interactively, making decisions in real-time. UX conventions, including informational error messages, progressive disclosure, multi-step wizards and confirmation dialogs, all assume a user who can pause, read, interpret and decide. Developer portals such as Backstage are excellent examples of this design philosophy: Rich, navigable and optimized for human judgment at every step.
An autonomous agent is a fundamentally different consumer. It operates on instructions encoded in advance, with no ability to pause on an ambiguous 403, intuit that a 429 means exponential backoff or recognize that a resource landed in the wrong region because a UI silently defaulted to us-east-1. Where a human reads and adapts, an agent executes and compounds.
The cost of this mismatch is not theoretical. Agents operating on ambiguous platform responses are one of the most common sources of infrastructure drift, runaway resource consumption and security policy violations in organizations that have deployed AI-driven automation at scale.
Solving it requires treating agents not as an edge case of your existing self-service model, but as a first-class consumer with distinct requirements that, when addressed properly, also make your platform significantly better for humans.
Key Insight
An agent that encounters an ambiguous response doesn’t pause and ask for help. It makes a decision, and that decision is encoded in its training, not in your documentation.
Designing Machine-Readable API Contracts
The most impactful change platform teams can make is investing in API contracts that are unambiguous by design. This is not simply a matter of following REST conventions or generating OpenAPI specs; it requires a deliberate rethinking of what self-describing means when the reader is a language model or an orchestration agent rather than a human developer.
Structured, Deterministic Error Responses
Human-readable error messages are worse than useless for agents: They are actively harmful because a language model may attempt to parse and act on them in unpredictable ways. Every error response from a platform API should carry a structured, machine-parseable payload that includes a stable error code (not just an HTTP status), a category (auth failure, rate limit, resource constraint, configuration error), a recommended action where one exists and a documentation URI.
A well-formed error response for an agent might look like this: An HTTP 403 with a body containing error_code: POLICY_VIOLATION, category: authorization, recommended_action: request_elevated_scope, scope_required: infra:write:prod and a link to the access request workflow. The agent doesn’t need to interpret language; it can branch on error_code deterministically.
Capability Discovery Over Documentation
Humans read docs; agents discover capabilities at runtime. Platform APIs intended for agent consumption should expose capability discovery endpoints: Structured responses that enumerate what an agent is authorized to do in its current context, what resources are available, what constraints apply and which operations are safe to attempt without triggering guardrails.
This is meaningfully different from a static API catalog. A capability discovery endpoint is context-aware: It responds based on the agent’s identity, its current scope, the target environment and active policy constraints. The result is a dynamic contract that prevents agents from attempting operations they cannot complete, reducing noise in your audit logs and eliminating the retry storms that follow unexpected permission denials.
Idempotency as a Platform Guarantee
Agents fail and retry. Networks partition. Orchestration layers lose state. Platform APIs that serve autonomous agents must treat idempotency not as a nice-to-have but as a first-class guarantee. Every mutating operation should support idempotency keys. Every resource creation endpoint should return identical results for duplicate requests with the same key. Every long-running operation should expose a stable, pollable status endpoint.
Without these guarantees, retry logic in agents becomes the source of your worst infrastructure incidents: Duplicate environments, split-brain resource states and billing anomalies that emerge weeks after the causal event.
Design Principle
If your API’s behavior changes based on whether an identical request has been made before, and you haven’t documented that explicitly, your platform is not safe for autonomous agents.
Identity and Access Management for Non-Human Principals
Access control is where most platform engineering teams have the largest gap. IAM systems evolved to manage human identities: Employees, contractors, service accounts tied to known humans. Autonomous agents introduce a class of principal that existing models handle poorly: Long-lived, high-frequency, cross-environment and fundamentally non-attributable to a single human accountable party.
Agent Identity as a First-Class Primitive
The foundational change is treating agent identity as a distinct primitive in your IAM model: Not a service account, not a user with a bot tag, but a purpose-built identity type with its own attribute schema. An agent identity should encode the agent’s purpose (deployment automation, cost optimization, security scanning), its operational scope (environments, teams, resource types), its authorization model (who approved it, under what policy) and its expected behavioral envelope (typical request volume, typical operation types).
This metadata is not just for governance documentation; it becomes the input for your policy engine. An agent identity tagged with purpose: deployment_automation and scope: Staging should be denied when it attempts to modify a production database, regardless of whether a static permission exists. The policy layer reasons about intent and context, not just credentials.
Just-in-Time and Scoped Credentials
Agents should never hold long-lived credentials with broad permissions. The correct model is just-in-time credential issuance: The agent authenticates with a platform-level identity, declares the operation it intends to perform and receives a time-bounded, scope-limited credential for exactly that operation. When the operation completes, or the credential expires, the scope evaporates.
This model requires platform investment: A credential vending service, an operation declaration protocol and the policy infrastructure to evaluate intent against permitted scope. Standards such as SPIFFE/SPIRE provide a strong foundation for workload identity federation in this model, enabling cryptographically verifiable identities for agents across environments without static secrets. The payoff is a dramatically reduced blast radius when an agent is compromised, misbehaves or is simply misconfigured.
Behavioral Anomaly as an Access Signal
Static access policies are necessary but not sufficient for agents. Since agents can acquire legitimate credentials and then operate outside their expected behavioral envelope, your access control model needs a dynamic layer that uses behavioral signals as an ongoing authorization input. An agent that suddenly begins making high-volume API calls to an environment it has never accessed, or that begins enumerating resources it has never previously queried, should trigger a policy evaluation, not just an alert.
This is a significant architectural commitment, but it is becoming increasingly tractable with modern policy engines such as Open Policy Agent (OPA) paired with Kubernetes admission controllers, which can evaluate behavioral context at the point of every platform API call.
Machine-Readable Golden Paths
Golden paths are the platform engineering community’s most effective tool for driving developer adoption of good practices. They work because they make the right thing the easy thing: A pre-approved, well-lit route through the infrastructure landscape that requires less decision-making than the alternatives.
For agents, golden paths need to be restructured around machine-consumability. Where a human follows a Backstage template or a guided portal wizard, an agent needs a structured workflow specification: Discoverable, executable and deterministic, with no required human judgment steps and explicit success and failure states.
Workflow Specifications Over UI Templates
Agent-facing golden paths should be expressed as workflow specifications in a structured, versionable format. Durable execution frameworks such as Temporal are well-suited to this pattern, providing explicit step sequencing, built-in retry semantics and auditable execution histories out of the box. Each specification defines its inputs (required and optional, with types and constraints), its preconditions (what must be true for the path to be valid), its steps (ordered, with explicit error-handling at each step), its guardrails (what the path will refuse to do and why) and its expected outputs.
These specifications serve double duty: They are the execution contract for agents and the governance documentation for platform teams. An agent executing a golden path is doing so against a versioned, audited specification, not improvising from a documentation page.
Guardrails as Encoded Policy
The most important design decision in agent-facing golden paths is where the guardrails live. For human users, guardrails can be implemented as soft stops: Warnings, confirmation dialogs, and required approvals. For agents, guardrails must be hard stops implemented in the platform layer, not in the agent’s logic, which is not a trust boundary.
This means the platform itself must enforce: No production changes without an explicit environment promotion step, no resource creation above a defined cost threshold without a budget check, no security group modifications without a compliance scan and no cross-account operations without an explicit authorization record. These are not suggestions in a README. They are invariants in your platform’s execution engine.
Architecture Note
Never rely on an agent’s own logic to enforce your platform’s guardrails. The agent is not a trust boundary. The platform is.
Observability for Agent-Driven Infrastructure
Observability in platforms designed for humans is built around two assumptions: That actions have human authors, and that humans will investigate anomalies. When agents are provisioning infrastructure, running deployments and modifying configurations autonomously, both assumptions break down.
Attribution as a First-Class Telemetry Dimension
Every action taken by an agent on your platform should carry a rich attribution record: The agent’s identity and version, the instruction or goal that triggered the action, the authorization chain that permitted it, the golden path (if any) being executed and the human or system that originally instantiated the agent for this task. This attribution should be a first-class dimension in your observability platform — queryable, aggregable and preserved across the full life cycle of any resource the agent touches.
Without attribution, your infrastructure audit trail becomes epistemically broken. You can see that a resource was created; however, you cannot determine whether it was created by a human, an agent acting correctly or an agent acting outside its intended scope.
Behavioral Baselines and Drift Detection
Agents have expected behavioral envelopes: Typical operation types, typical request rates and typical resource targets. Your observability platform should build baselines for each deployed agent identity and expose drift detection as a platform-level service. Significant deviation from the baseline, in volume, in resource scope or in operation type distribution, should surface as a platform signal, not just an agent metric.
This is fundamentally different from application performance monitoring. You are not measuring whether the agent is healthy; you are measuring whether the agent is doing what it was authorized to do.
Audit-Grade Immutable Logs
Agent-driven infrastructure actions must be logged to an audit-grade, append-only, tamper-evident store. This is not a nice-to-have; in regulated industries, it is a compliance requirement. But even outside regulated contexts, it is the foundational prerequisite for any post-incident analysis when an agent causes an outage, drives unexpected cost or creates a security exposure. The log must be immutable because the agent, or the system that controls it, is a potential adversary in the worst case.
Governance: Who is Accountable When an Agent Breaks Something?
The governance question is the one most platform teams are least prepared for, and the one that will generate the most organizational friction as agent-driven automation scales. When an agent provisions an insecure resource, consumes the budget unexpectedly or causes a production incident, the accountability model needs to be defined before the incident, not in the middle of it.
Agent Provenance and Approval Chains
Every deployed agent operating on your platform should have a provenance record: Who approved it, under what policy, with what operational scope, for what purpose and with what review cadence. This record is the governance artifact that connects agent actions to human accountability. It is also the document that gets reviewed when something goes wrong.
Platform teams should resist the temptation to treat agents as inherently trustworthy because they were approved once. Approval should be time-bounded, scope-bounded and subject to behavioral review. An agent approved for staging deployment automation six months ago should not automatically retain permission to operate in production as the organization’s infrastructure evolves.
Policy as Code for Agent Operations
Governance policies for agent operations should be expressed as code, versioned alongside your infrastructure definitions and enforced by your platform’s policy engine — not by convention, documentation or human review. Tools such as OPA/Gatekeeper make this pattern operationally mature on Kubernetes-based platforms, enabling policy evaluation at admission time with full auditability. Policy as code gives you traceability (every policy change is a commit), testability (you can validate policies against historical agent actions) and enforceability (violations are blocked, not flagged after the fact).
The policy layer should reason about agent intent, not just agent credentials. An agent with write access to staging environments should be blocked from production not because it lacks a credential, but because its declared purpose does not include production operations and the policy engine knows that.
A Practical Maturity Model
Platform teams moving toward agent-ready infrastructure rarely need to rebuild everything at once. The following progression offers a practical maturity arc:
- Structured Error Contracts: Add machine-parseable error payloads to existing APIs. This is the highest-leverage starting point and requires no architectural changes.
- Agent Identity Primitives: Extend your IAM model to support agent identity as a distinct type. Even a lightweight extension, such as a purpose tag or a scope attribute, provides immediate governance value.
- Just-in-Time Credentials: Implement a credential vending service for the most sensitive operation classes first (production changes, cross-account operations, security group modifications).
- Agent-Facing Golden Paths: Convert your two or three most commonly automated workflows into machine-readable specifications with hard guardrails.
- Attribution Observability: Add agent attribution as a telemetry dimension. Start with your audit log, then expand to your metrics and trace data.
- Behavioral Baselines: Once attribution is in place, build behavioral baselines and surface drift as a platform signal.
- Policy-as-Code Governance: Express agent authorization policies in code, enforce them in the platform layer and review them on a defined cadence.
The Platform Engineering Mandate
The shift to autonomous agents operating on your infrastructure is not a future scenario to plan for. It is happening now, and in most organizations, it is happening faster than the platform governance model is evolving to meet it.
Platform engineering teams have a choice: Adapt the self-service model proactively, with machine-readable contracts, agent-first access control and hard guardrails baked into the platform layer, or watch agents acquire credentials and operate on a platform that was never designed for them, generating drift, risk and incidents that are difficult to attribute and harder to prevent.
The good news is that agent-ready platform design is not a departure from good platform engineering; it is the logical extension of it. Every principle that makes a platform good for humans (determinism, observability, guardrails, paved paths) is the same principle that makes it safe for agents. The difference is in the enforcement: For agents, none of it can be advisory.
Build the platform as if the agents are already here…because they are.